





In this tutorial you can find how to add text labels to a scatterplot in Python?. You will find examples on how to add labels for all points or only for some of them.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.pyplot import figure
from matplotlib.lines import Line2D
df = pd.read_csv("https://raw.githubusercontent.com/softhints/dataplotplus/master/data/happyscore_income.csv")
ineq = df.income_inequality
ineq_min = min(ineq)
ineq_max = max(ineq)
norm_ineq = (ineq - ineq_min)/(ineq_max - ineq_min)
df['norm_ineq'] = norm_ineq
figure(num=None, figsize=(18, 16), dpi=100, facecolor='w', edgecolor='k')
plt.xlabel('Income')
plt.ylabel('Happy Score')
region = df.region.unique()
print(region[0])
df.region = df.region.replace('\'','')
print(region[0])
region_colors = {'Central and Eastern Europe':'red', 'Western Europe':'red',
'Sub-Saharan Africa':'green', 'Middle East and Northern Africa':'green',
'North America':'blue', 'Latin America and Caribbean':'blue',
'Southeastern Asia':'cyan', 'Southern Asia':'cyan', 'Eastern Asia':'cyan',
'Australia and New Zealand':'purple'}
print(region_colors['Central and Eastern Europe'])
for i,j in df.iterrows():
reg_color = region_colors.get(j.region.replace('\'',''), 'black')
plt.scatter(df.avg_income[i], df.happyScore[i], s=df.avg_income[i] / 10, alpha = 0.25, color=reg_color)
custom = [ Line2D([], [], marker='.', color=i, linestyle='None', markersize=25) for i in region_colors.values()]
plt.legend(custom, region_colors.keys(), fontsize=15)
[plt.text(x=row['avg_income'], y=row['happyScore'], s=row['country']) for k,row in df.iterrows() if 'Europe' in row.region]
plt.show()
result:
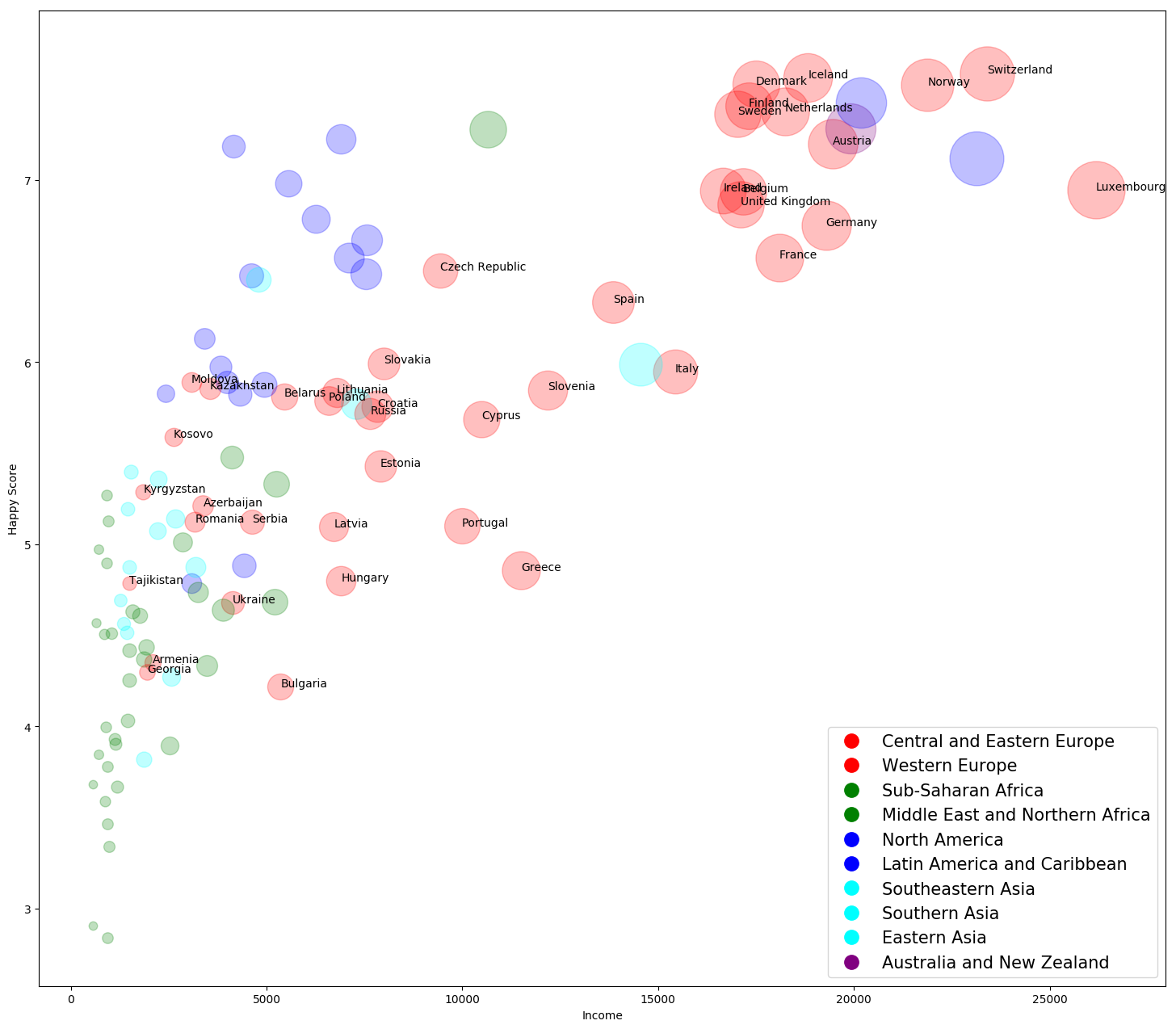
Add text labels to Data points in Scatterplot
The addition of the labels to each or all data points happens in this line:
[plt.text(x=row['avg_income'], y=row['happyScore'], s=row['country']) for k,row in df.iterrows() if 'Europe' in row.region]
We are using Python's list comprehensions. Iterating through all rows of the original DataFrame.
Going to add labels only for the region 'Europe'. For each x and y we are getting the country name and create new list in form of:
[Text(2096.76, 4.35, 'Armenia'),
Text(19457.04, 7.2, 'Austria'),
Text(3381.600000000001, 5.2120000000000015, 'Azerbaijan'),
Text(17168.505, 6.937, 'Belgium'),
Text(5354.82, 4.218, 'Bulgaria'),
Text(5453.933333333333, 5.813, 'Belarus'),
If you like to label all points you need to remove the if clause:
[plt.text(x=row['avg_income'], y=row['happyScore'], s=row['country']) for k,row in df.iterrows()]